
AI Content Detector Report 2026: The Complete Accuracy Study

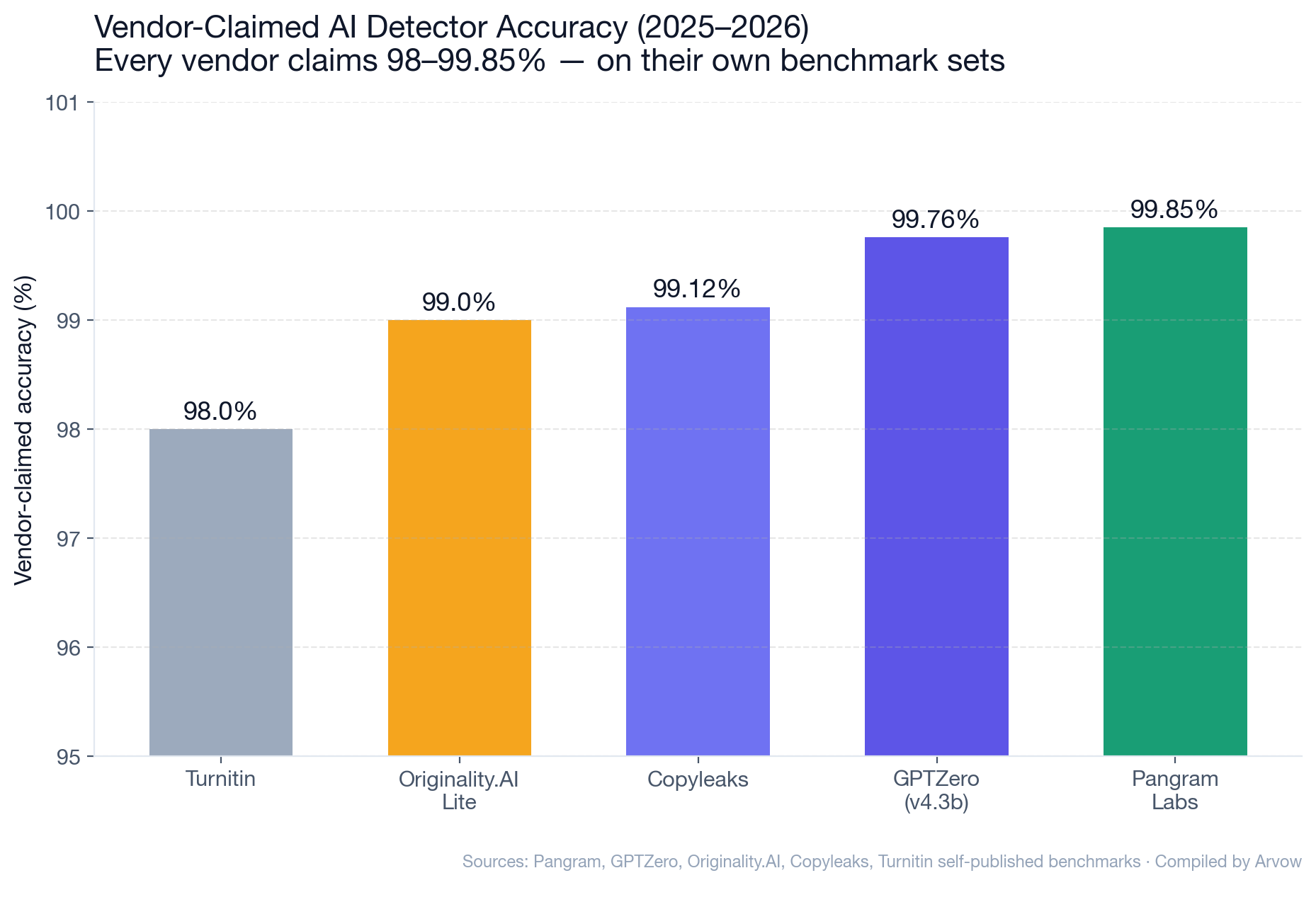
AI content detectors are a $1.79 billion industry projected to hit $6.96 billion by 2032 (Coherent Market Insights, 21.4% CAGR) — yet the most rigorous academic study on the category (Stanford, 7 detectors × 91 TOEFL essays) found that 61.3% of human-written non-native English essays were flagged as AI on average, with all 7 detectors unanimously misclassifying 19.8%. OpenAI shut down its own classifier in July 2023 after measuring just 26% accuracy on AI text and a 9% false positive rate. Vanderbilt disabled Turnitin’s AI detector in August 2023 after calculating that the vendor-claimed “1% FPR” would still wrongly flag ~750 of their 75,000 annual student papers. And in independent testing, Copyleaks’ self-claimed 99.12% accuracy collapses to 66% in Scribbr’s 12-tool comparison — a 33-point gap between marketing and reality.
We aggregated data from the Stanford GPT-detector bias study, RAID’s 6.28-million-text benchmark (UPenn / UCL / King’s College / CMU), the Pangram Labs 30-tool 2026 comparison, GPTZero’s 4-domain benchmarking, Originality.AI’s 14-study meta-analysis (16,000+ samples), Vanderbilt and Penn State institutional policy, Semrush’s 42K-page ranking study, Graphite’s Five Percent project, the 2026 Anangsha humanizer panel, OpenAI’s own classifier disclosure and 20+ other primary sources to compile the most rigorous, methodology-checked AI content detector report available in 2026. Where studies disagree (and they do — wildly), we explain why. Every stat below is dated, sourced, and methodology-checked.
$1.79B AI content detection market in 2025 (projected $6.96B by 2032) |
61.3% of TOEFL essays falsely flagged as AI (Stanford, n=91) |
26% accuracy of OpenAI's own classifier (shut down 2023) |
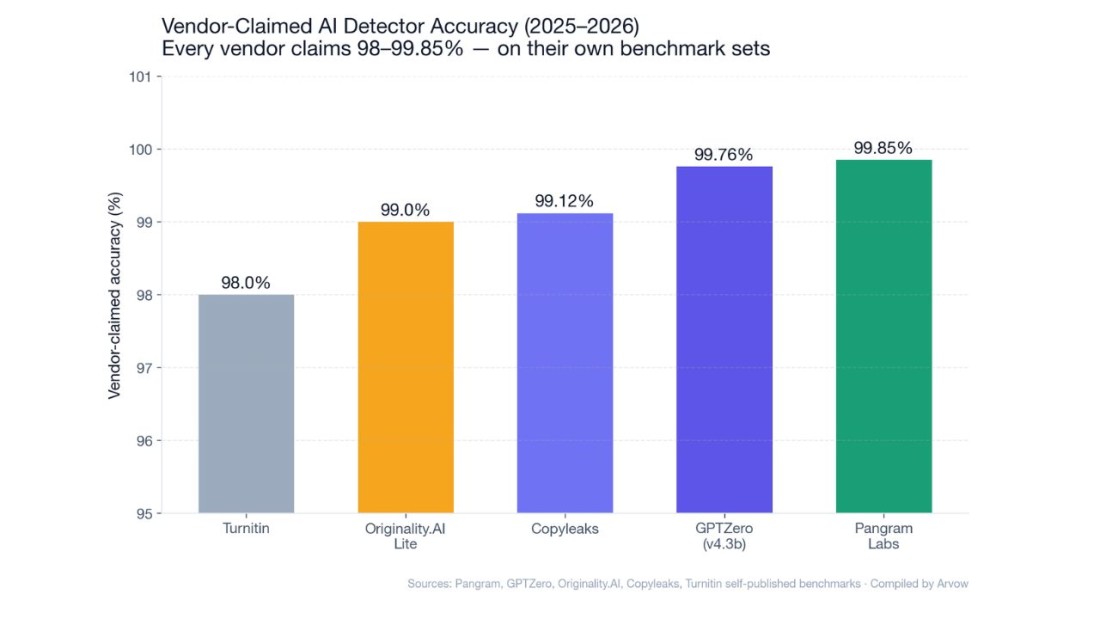
99.85% Pangram's claimed accuracy vs 33-point vendor-vs-reality gap |
Key Takeaways (2026)
- The vendor numbers are inflated: Pangram claims 99.85% accuracy. GPTZero claims 99.76%. Originality.AI claims 99%. Copyleaks claims 99.12%. Independent tests find real-world accuracy 66–92% depending on the detector and dataset.
- The Stanford bias finding is the foundational academic critique: 61.3% average false-positive rate on non-native English essays. All 7 detectors unanimously misclassified 19.8% of TOEFL essays. The 2023 Stanford / James Zou paper drove every subsequent institutional pushback.
- Turnitin’s real false positive rate is 5–20× the vendor claim: Turnitin advertises “<1% FPR.” Independent analyses find 5–20% in real classroom use (University of San Diego Legal Research Center).
- OpenAI itself couldn’t make detection work: OpenAI’s classifier — launched January 2023 — was shut down on July 20, 2023 after measuring 26% accuracy on AI text and 9% false positive rate.
- The university pushback is institutional, not anecdotal: Vanderbilt (Aug 2023), Michigan State, Northwestern, UT Austin, Penn State all disabled or recommended against Turnitin’s AI detection.
- In the most rigorous benchmark (RAID, 6.28M texts), Originality.AI ranked #1 in 9 of 11 adversarial tests — but GPTZero’s cross-analysis of the same data places Originality at 83% accuracy with 4.79% FPR (vs Originality’s claimed 0.5%).
- Bundled “AI detector” features in writing tools don’t work: Pangram’s 2026 30-tool head-to-head: Writer, Grammarly, SurgeGraph, BrandWell, and Decopy AI scored 0/9 on AI detection. Only Pangram and Copyleaks scored perfect 9/9 AI + 3/3 human.
- General-purpose humanizers are coin-flip effective: QuillBot AI humanizer bypass rate in 2026: 47.4%. Grammarly’s humanizer (launched late 2025): 43.2%.
- AI content can rank — at lower SERP positions: Semrush 42K-page study: position 1 is 8× more likely to be human-written. From position 5 onward, the human/AI gap narrows. Graphite’s Five Percent: 86% of articles ranking on Google are human-written.
- Multilingual is the open frontier: GPTZero claims 0.09% FPR on 24-language text. Originality.AI on the same set: 14.81% FPR. Detector reliability outside English is structurally low.
1. The AI Detector Market in 2026
The category went from niche to mass-market in 36 months.
Market sizing
- Coherent Market Insights: AI Content Detection Software Market valued at $1.79B in 2025, projected $6.96B by 2032 at 21.4% CAGR.
- MarketsAndMarkets (different definition): AI Detector market at $0.58B in 2025 → $2.06B in 2030 at 28.8% CAGR.
- The disagreement is real (definitional — does “detection” include plagiarism, deepfake image, audio detection?) — but the directional growth (~20–29% CAGR) is consistent.
Segment composition
- Plagiarism & Academic Integrity is 35.6% of market share (Coherent, 2025) — education buys more detector seats than content marketing.
- Text-based detection: 37.3% of total volume. Image / audio / video detection makes up the rest.
- North America: 43.4% of global market — same US-dominance pattern we documented in our SEO Agency Statistics 2026.
What’s driving the growth
The detector market is reactive to the upstream AI prevalence: - 74.2% of newly created web pages contain AI-generated content (Ahrefs 900K-page study — see our pSEO piece §6). - 35% of newly published websites are AI-generated (Stanford / Imperial / Internet Archive, using Pangram Labs’ classifier). - Universities, publishers, and search engines all need detection workflows. The buyer base is genuinely enormous.
The economics are simple: detection is sold as a defense against the AI flood, even when independent evidence increasingly shows that defense is unreliable.
2. The Vendor-Claimed Accuracy Numbers
Every vendor publishes their own benchmarks with their own test sets. The 99% club is crowded.
Pangram Labs
- 99.85% accuracy with 0.19% false positive rate across thousands of examples covering 10 writing categories and 8 LLMs.
- Methodology: “hard negative mining with synthetic mirrors” — pairing every human document with an AI-generated mirror of the same topic / length. Claimed to reduce FPR by 100× vs naive training.
GPTZero (v4.3b)
- 99.76% accuracy, 0.08% FPR, 99.60% recall, 99.93% precision across 4 domains.
- On humanized text: 95.70% accuracy, 0.21% FPR.
- On multilingual (24 languages): 98.79% accuracy, 0.09% FPR.
- Methodology: 1,000 human + 1,000 LLM-generated texts per domain.
Originality.AI
- Lite v1.0.2: 99% accuracy on OpenAI, Gemini, Claude, DeepSeek, 0.5% FPR.
- Turbo 3.0.2: 99%+ accuracy, 1.5% FPR.
Copyleaks
- 99.12% accuracy, <1% FPR.
- The headline benchmark: 99% accuracy / 0.2% FPR on 50 human + 50 AI literature samples (a tiny sample — methodology weakness obvious).
Turnitin
- Advertised 98% accuracy with <1% false positive rate.
- Independent analyses find 5–20% real-world FPR (University of San Diego Legal Research Center).
These numbers can’t all be true. They’re the same category, on different test sets, evaluated by the vendor themselves. The honest read: vendor benchmarks are upper bounds, not real-world expectations.
From Arvow: Arvow’s AI SEO Agent produces content with structural signals (schema, internal linking, citation density, FAQ formatting) that drive ranking regardless of detector classification — because the ranking signal is structural, not “detect-AI vs detect-human.” Per our pSEO piece, the surviving AI content shares those structural patterns. Discover the AI SEO Agent →
3. The Independent Testing Reality
Where vendor claims meet third-party benchmarks.
The RAID benchmark (the gold standard)
- 6,287,820 texts across 8 domains, 11 LLMs, 11 adversarial attacks. 12 detectors tested.
- Conducted by UPenn, University College London, King’s College London, and Carnegie Mellon University.
- The most rigorous AI detection benchmark in the literature.
Origin Originality.AI’s RAID result (as reported by Originality.AI): - Ranked #1 in 9 of 11 adversarial tests. - Base accuracy: 85%. Paraphrased content: 96.7%.
Originality.AI’s RAID result (as reported by GPTZero): - 83% accuracy, 4.79% false positive rate — nearly 10× Originality’s own claim of 0.5%.
Same dataset, opposite framings. The honest reading: in adversarial conditions, even the leading detector has a ~5% real-world FPR — not the 0.5% claimed in marketing.
Scribbr’s 12-tool independent comparison
- Copyleaks dropped from claimed 99.12% to 66% accuracy in Scribbr’s independent test.
- GPTZero held at 99.3% in the same comparison — but with 5% false positive rate computed for Copyleaks (1 in 20 human documents wrongly flagged).
CyberNews on Originality.AI
- 92% accuracy with 5.7% FPR — triangulates the ~85–92% real-world accuracy and ~5% real-world FPR for Originality.
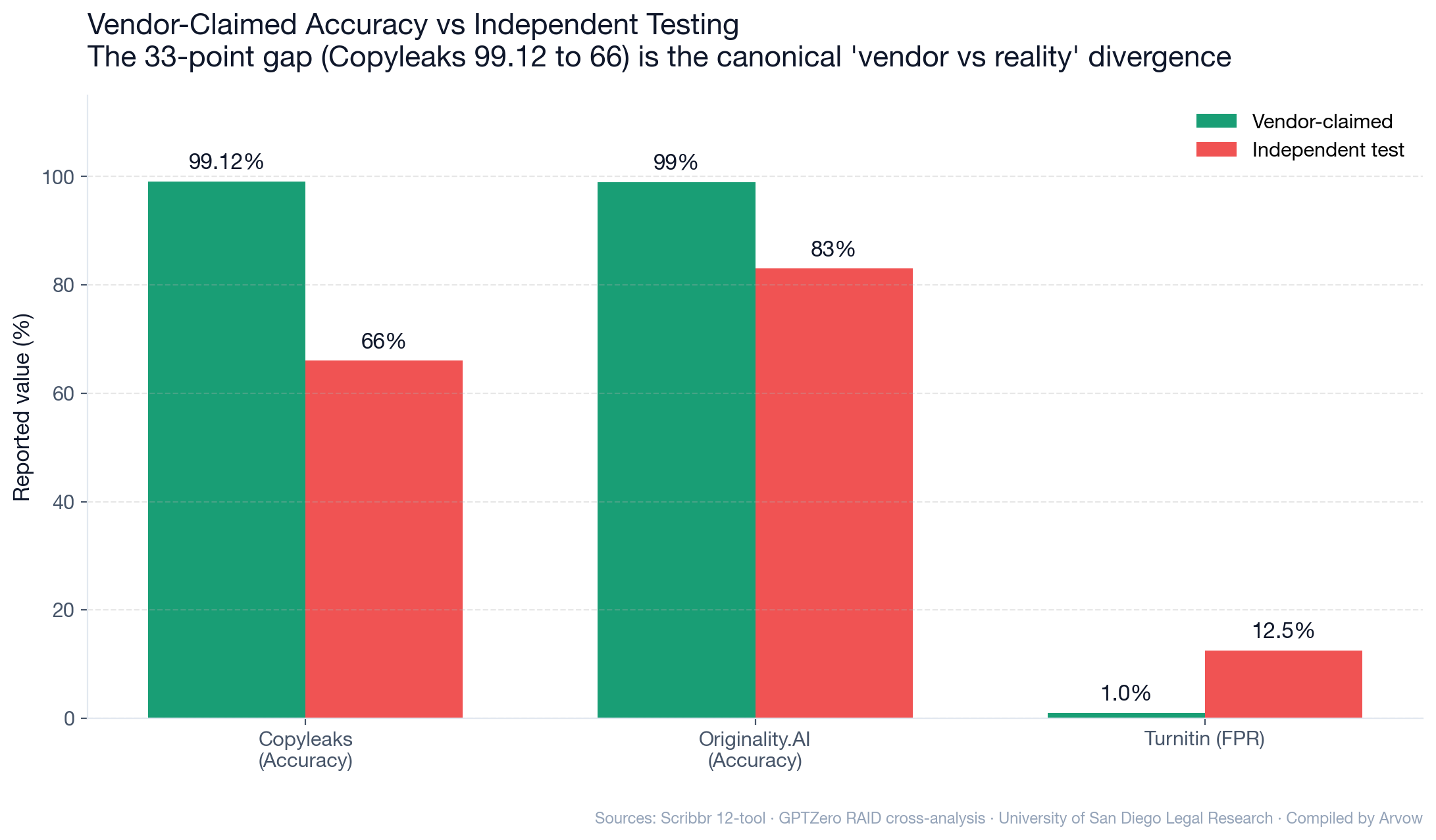
Pangram Labs 30-tool comparison (2026)
The most recent comprehensive head-to-head. Methodology: 9 AI texts (3 from GPT-4o, 3 from Gemini 2.0, 3 from Claude 3.7) + 3 human texts. Pass criteria: ≥75% AI score on AI, ≤25% on human.
Top tier (both AI and human detection): | Tool | AI detection | Human detection | |—|—|—| | Pangram Labs | 9/9 (100%) | 3/3 (100%) | | Copyleaks | 9/9 (100%) | 3/3 (100%) |
Mid tier: | Tool | AI detection | Human detection | |—|—|—| | GPTZero | 7/9 (78%) | 3/3 (100%) | | Originality.AI | 7/9 (77%) | 3/3 (100%) | | Sapling.ai | 6/9 (67%) | 3/3 (100%) |
Bottom tier — bundled “AI detector” features: - Writer, Grammarly, SurgeGraph, BrandWell, Decopy AI: 0/9 on AI detection. - ContentDetector.ai, Decopy AI: 0/3 on human detection (false-positive-on-everything).
The bundled-feature bottom tier is the most important takeaway: the “AI detector” inside your writing tool is functionally non-functional.
⚠️ Methodology caveat: Pangram ran this comparison, so it’s vendor-tested. But the methodology is explicit and the pass criteria are tight. Triangulates with the Scribbr, CyberNews, and RAID independent findings.
4. The False Positive Problem (And the Non-Native English Bias)
This is where AI detection runs into ethical and operational failure.
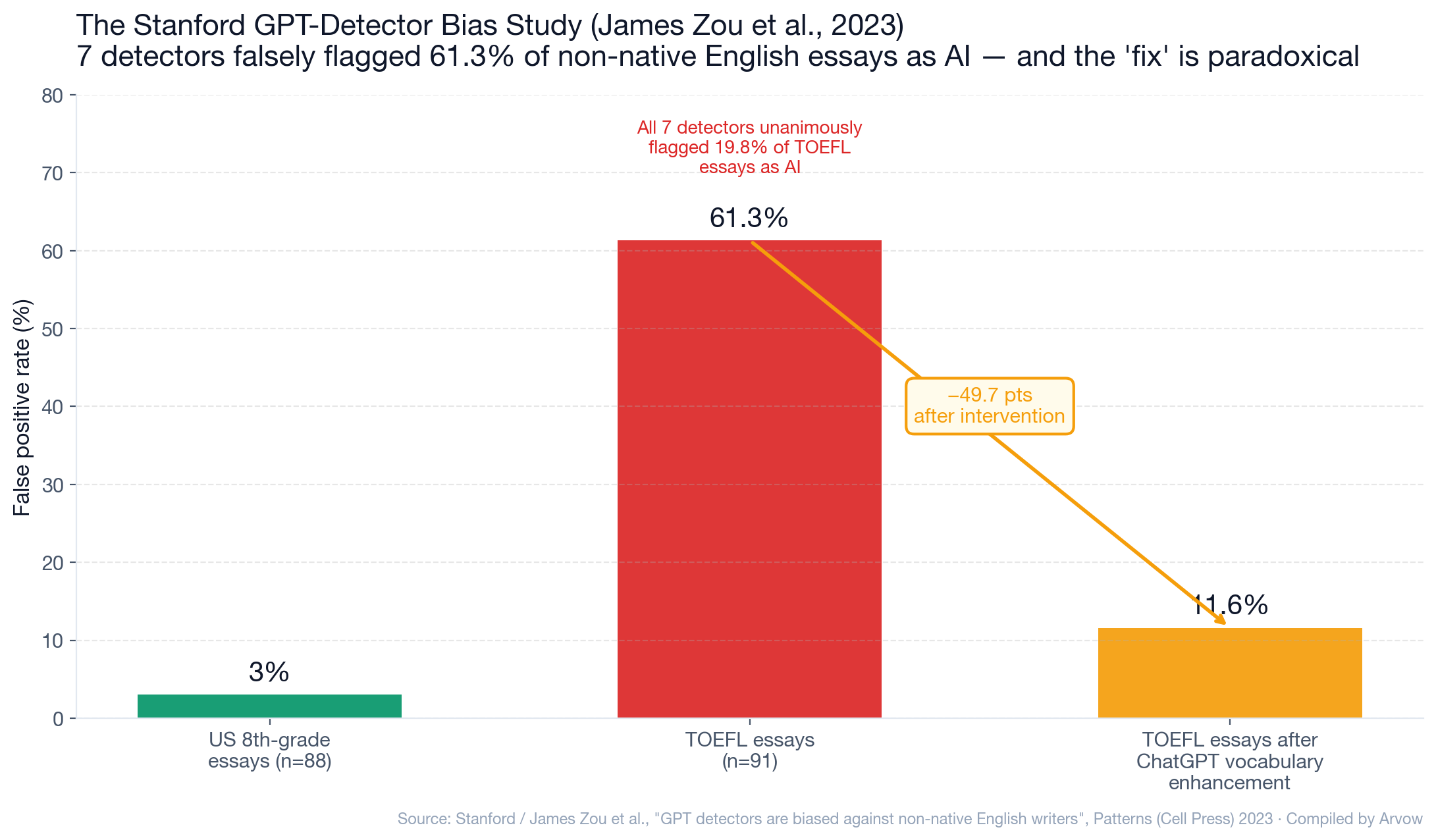
The Stanford GPT-detector bias study
The single most-cited academic critique of AI detectors, by James Zou and colleagues, published in Patterns (Cell Press) in April 2023.
Methodology: - 7 widely-used commercial GPT detectors. - 91 TOEFL essays from a Chinese forum (non-native English writers). - 88 US 8th-grade ASAP essays (native English writers).
Findings: - US student essays were correctly classified (low false-positive rate). - TOEFL essays were misclassified as AI-generated at an average rate of 61.3%. - All 7 detectors unanimously misclassified 19.8% of TOEFL essays. - At least one detector flagged 97.8% of TOEFL essays as AI-written.
The “perplexity” mechanism
Detectors typically score text based on perplexity — how “predictable” the text is to an LLM. Non-native English speakers tend to have lower lexical richness, lexical diversity, and syntactic complexity. Their writing is more “predictable” in detector statistical models — and gets misclassified as AI.
The paradox: ChatGPT-rewriting reduces false positives
The Stanford team tested the obvious counter-intervention: have ChatGPT enhance TOEFL essay vocabulary toward native-speaker style.
- False-positive rate dropped from 61.3% to 11.6% — a 49.7 percentage-point reduction.
In other words: using ChatGPT to rewrite human writing makes the human writing get less flagged as AI. The detector is measuring writing sophistication, not generation source.
The neurodivergent dimension
- Students with autism, ADHD, and dyslexia are flagged at higher rates (University of Nebraska-Lincoln institutional report).
- The UK’s Office of the Independent Adjudicator published 6 case summaries in July 2025 — one involved an autistic student given a mark of zero based on detector flagging.
Vanderbilt’s institutional math
Vanderbilt disabled Turnitin’s AI detector on August 16, 2023. The triggering calculation:
- Turnitin’s claimed FPR: <1%
- Vanderbilt papers submitted in 2022: 75,000
- Implied wrongly-flagged: ~750 students per year
- “Even if Turnitin’s number is right, that’s 750 false accusations per year. We can’t operate that way.”
Plus the unacceptable demographic bias against international students.
Institutional pushback (the 2023–2025 university policy collapse)
- Vanderbilt (Aug 2023): disabled
- Michigan State: disabled
- Northwestern: disabled
- University of Texas Austin: disabled
- Penn State: recommended against use, “unreliable”
- University at Buffalo student petition launched 2025 after personal false-flag incident
Real-world FPR data
- Vendor-claimed FPR (Turnitin): <1%
- Independent analyses: 5–20% real-world FPR
- Vanderbilt-modeled FPR: 1% (still operationally unworkable at 75,000-paper scale)
A 5–20% real-world FPR means 1 in 5 to 1 in 20 human documents are wrongly flagged.
5. The Humanizer / Paraphraser Arms Race
If detection is unreliable, what about evasion?
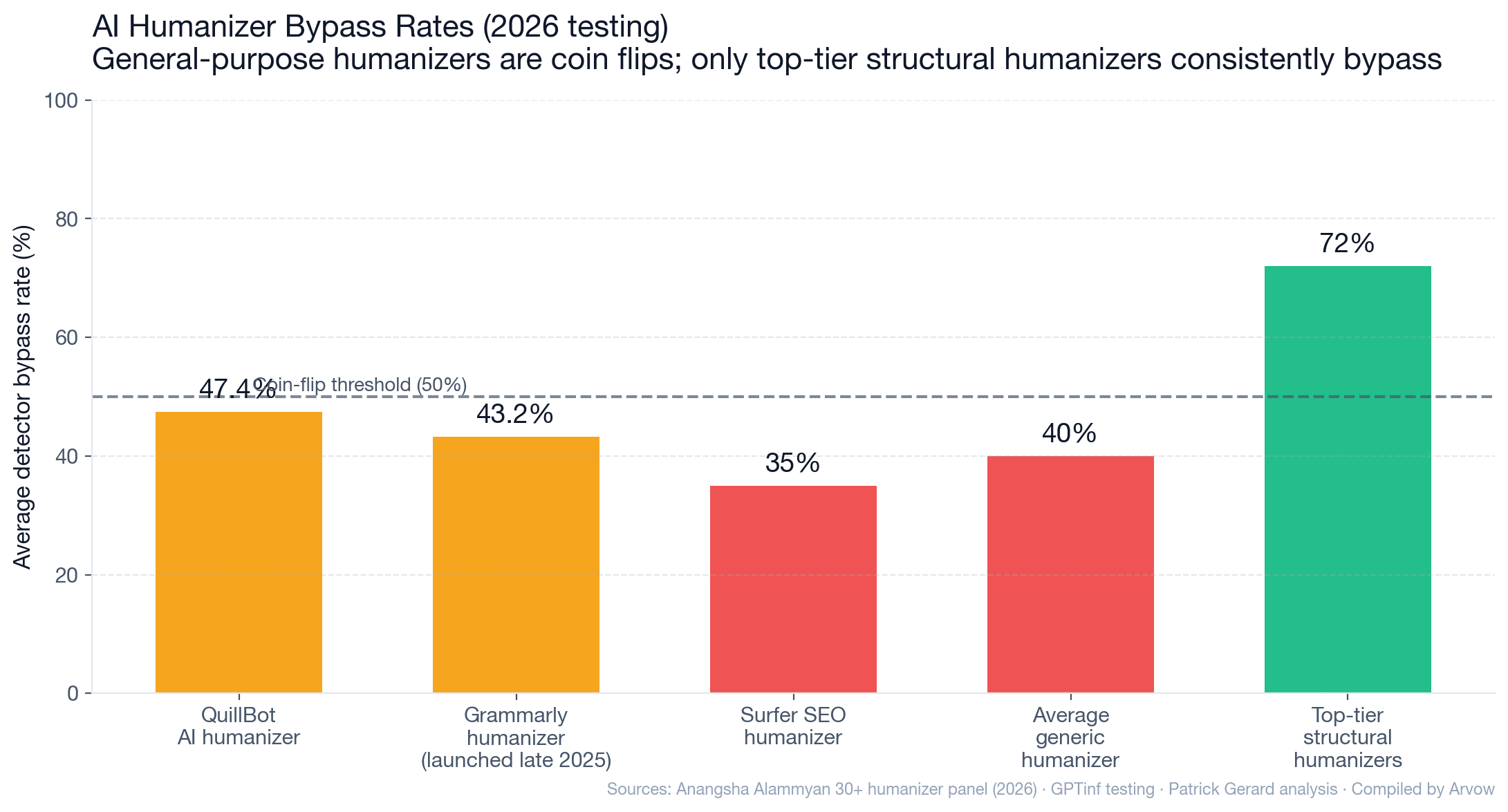
The 2026 humanizer landscape
Per Anangsha Alammyan’s 30+ tool test (2026, against 5 detectors):
- QuillBot AI humanizer: 47.4% average bypass rate — essentially a coin flip.
- Grammarly AI humanizer (launched late 2025): 43.2% average bypass.
- General-purpose humanizers are not reliably effective.
Basic paraphrasing is obsolete
- Detectors now reliably catch QuillBot synonym swapping and simple paraphrasers.
- Effective humanization requires statistical-structure changes, not vocabulary swaps (Patrick Gerard analysis).
The DAMAGE academic study
Published January 2025: qualitative audit of 19 humanizers, categorized into 3 tiers by transformation quality. The paper explicitly frames the humanizer/detector relationship as an “arms race” — adversarial evolution likely to continue indefinitely.
What still works (sometimes)
- Top-tier humanizers (the ones operating on sentence structure, not just vocabulary) can achieve 70%+ bypass against specific detectors — but performance is non-portable across detectors.
- “Undetectable AI bypass effectiveness varies dramatically by content type, rewriting mode, and target detector” (GPTinf testing).
What’s coming
- Watermarking proposals from OpenAI and Anthropic could obsolete the entire downstream detector category if shipped. As of May 2026, neither has shipped at scale.
- Detector vendors are training on humanizer outputs, so each humanizer release triggers a detector update within months.
The honest read: there is no reliable way for a human to consistently bypass 2026 detection across all detectors. And there is no reliable way for a 2026 detector to consistently catch all AI content. Both sides are running with high error rates.
6. OpenAI’s Own Concession: Detection Doesn’t Work
The most-overlooked data point in the entire category.
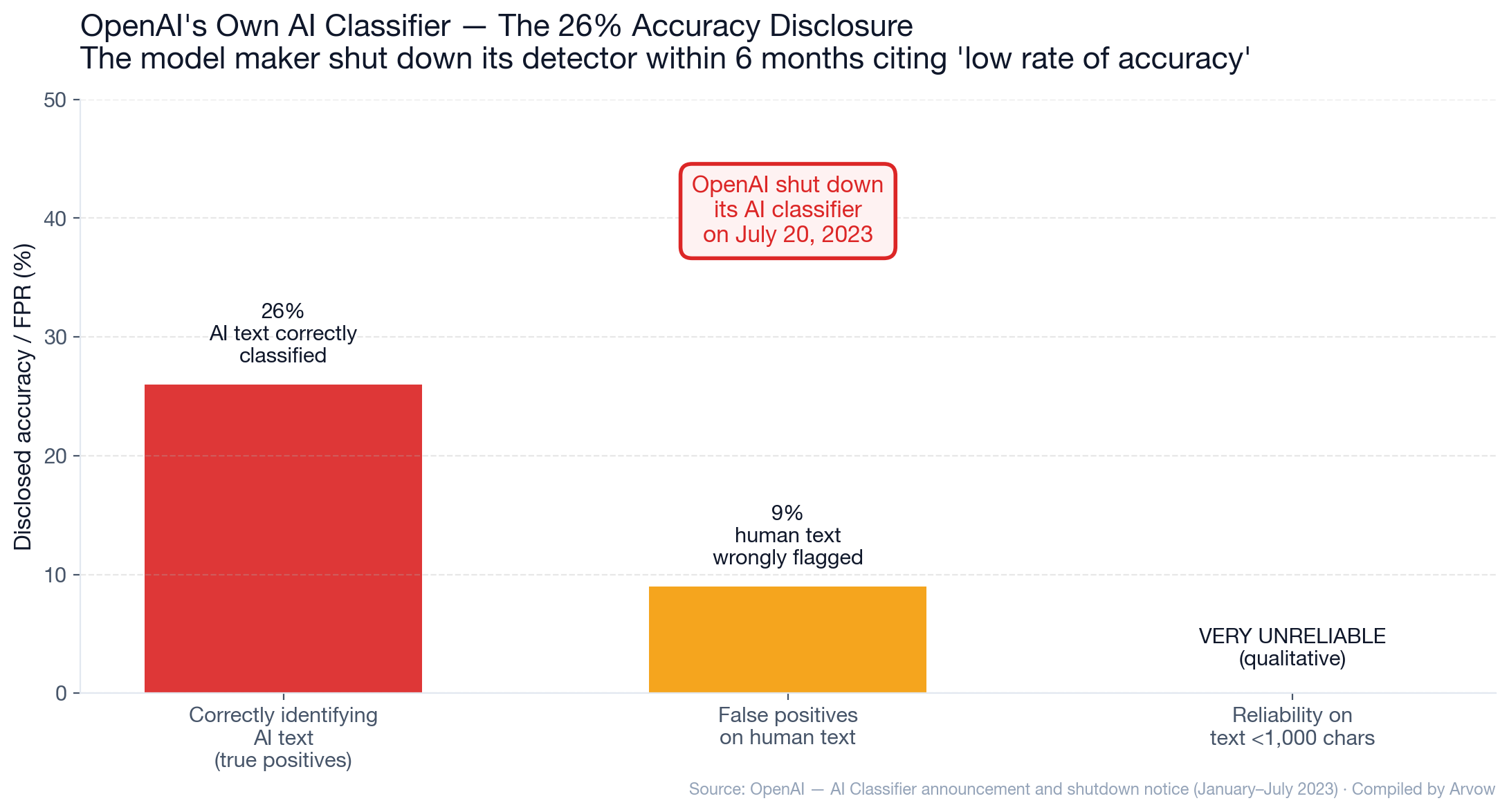
The timeline
- January 31, 2023: OpenAI launches its AI text classifier.
- July 20, 2023: OpenAI shuts down the classifier due to “low rate of accuracy.”
The disclosed performance
- 26% accuracy on AI-written text (“likely AI-written” correct classification).
- 9% false positive rate on human text.
- “Very unreliable” on texts below 1,000 characters.
What this means
The company that built the underlying LLM technology was unable, in 2023, to reliably classify its own output. They concluded the problem wasn’t solvable at the quality bar required to ship publicly.
That doesn’t mean detection is permanently impossible — Pangram and others have made significant progress since. But it does mean: anyone selling 99% accuracy in a category where the model maker concluded 26% in 2023 should be evaluated with extreme skepticism.
Short-content remains broken
Even modern detectors significantly degrade on texts under 250–300 characters. Both Turnitin and OpenAI’s documented classifier explicitly note this. Short-form AI content (Tweet-length, comment-length, ad-copy-length) is functionally undetectable at production-quality FPR.
7. AI Content & Google Ranking — What Detector Data Reveals
The intersection where detection meets SEO economics.
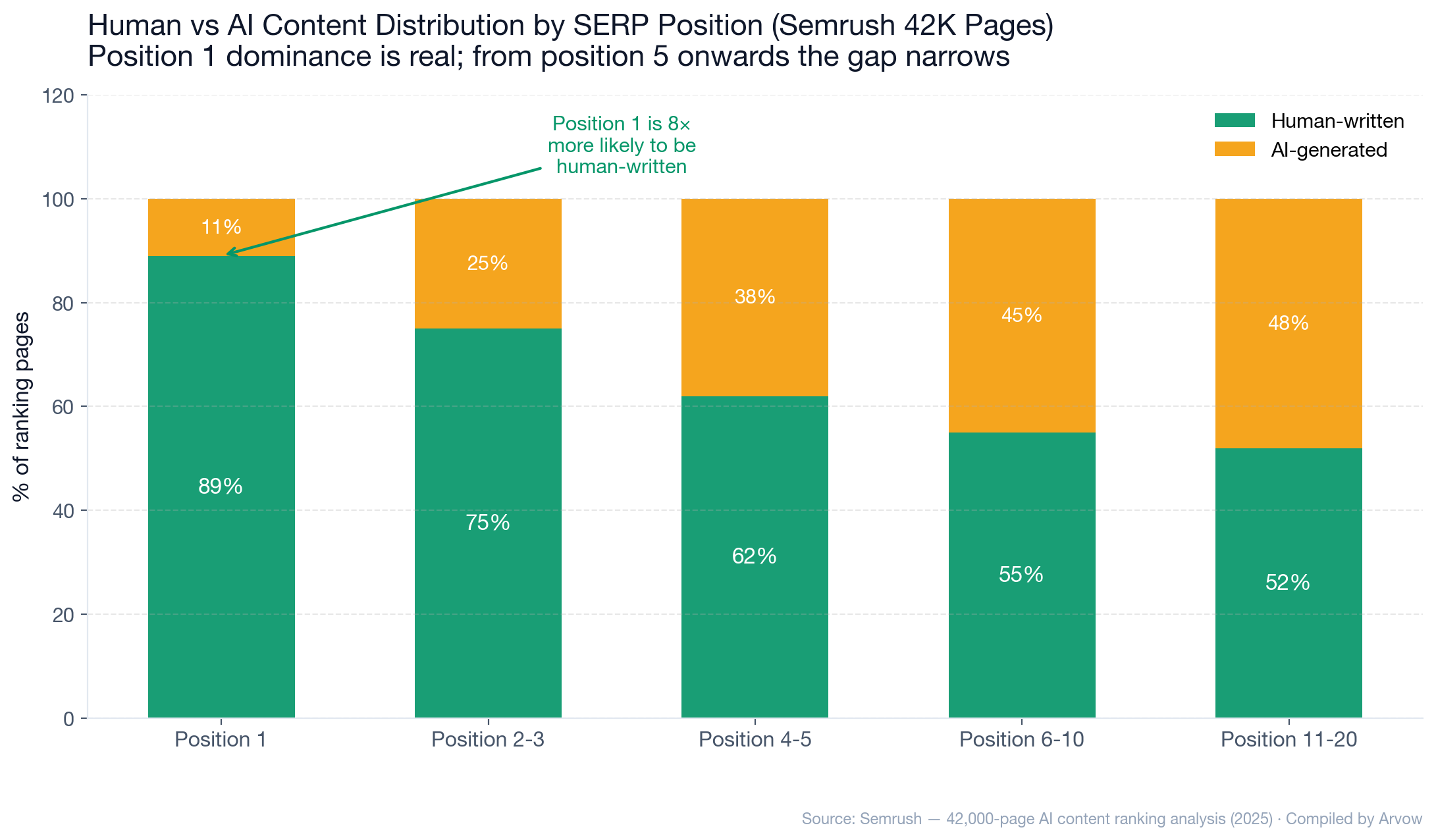
Semrush 42K-page study (2025)
- Position 1 results are 8× more likely to be human-written than AI-generated.
- From position 5 onwards, the gap narrows substantially — AI content holds its own in mid-tier rankings.
- If most teams are benchmarking against “ranking on page one,” human content pulls clearly ahead. Beyond position 5, “AI vs human” is roughly parity.
Graphite Five Percent
- 86% of articles ranking on Google Search are written by humans.
- 14% are AI-generated.
- 82% of articles cited by ChatGPT and Perplexity are human-written.
Rankability 487-result study
- 83% of top Google search results were classified as non-AI by Originality.AI.
- Sample explicitly noted as “tiny case study with a small sample” — but directional agreement with Semrush and Graphite.
The “82% of high-ranking pages have some AI content” counter
- A widely-cited number suggests ~82% of high-ranking pages contain at least some AI-generated text.
- Primary source attribution is inconsistent — multiple secondary citations, no clear single primary study.
- Both claims (14% AI ranking + 82% has-some-AI) can be true: high-ranking pages may have AI assistance for specific sections, but the dominant authorial voice tested as human.
What Google actually says
Google’s official position (Search Central, multiple 2024 updates): - AI content is not penalized as a category. - SpamBrain + helpful content system target low-quality content regardless of generation method. - Manual actions for “scaled content abuse” have targeted specific sites (see Forbes Advisor case in our Agency Statistics piece §10).
The detector data triangulates with the ranking data: AI content can rank, but the top-of-SERP positions skew strongly human. The reasons aren’t simple “Google detected AI” — they’re a combination of editorial depth, structural signals, brand authority, and the structural signals we document in our pSEO piece §12.
8. The Detector Vendor Comparison Matrix
Synthesizing across all the data — what each detector is actually good for in 2026.
Pangram Labs
- Strengths: Highest claimed accuracy. Used by Stanford / Imperial academic team as their classifier of choice for AI-website prevalence research. Strong on pure AI content. Transparent methodology.
- Weaknesses: Drops to 83.64% on humanized text (vs GPTZero’s 95.70%).
- Use case: Academic-grade detection on clean AI content.
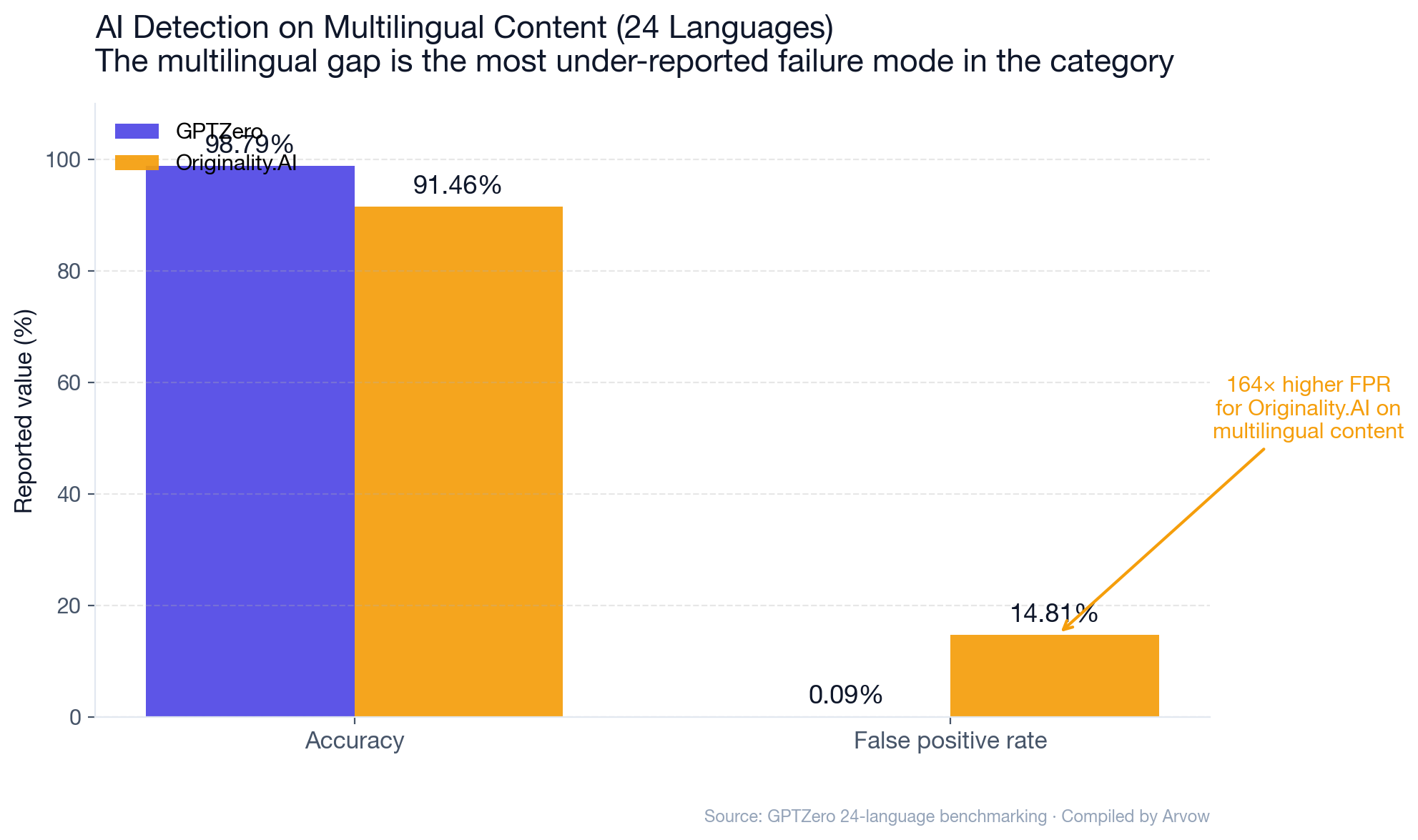
GPTZero
- Strengths: Lowest claimed FPR (0.08%). Best disclosed performance on humanized text. Multilingual accuracy (24 languages: 98.79% / 0.09% FPR).
- Weaknesses: Real-world performance still 5–20% FPR per institutional reports (similar to others).
- Use case: Education-side flagging where false-positive risk is high-cost.
Originality.AI
- Strengths: Ranked #1 in 9 of 11 RAID adversarial tests (per their own reporting). Strong on paraphrased content (96.7%).
- Weaknesses: GPTZero’s RAID cross-analysis places real FPR at 4.79% (vs claimed 0.5%). Drops to 14.81% FPR on multilingual content.
- Use case: Content marketing / SEO publishing pre-checks.
Copyleaks
- Strengths: Tied with Pangram (9/9 AI + 3/3 human) in the 2026 Pangram comparison.
- Weaknesses: Self-claimed 99.12% drops to 66% in Scribbr’s independent test. Real FPR ~5% per independent analyses.
- Use case: Enterprise plagiarism + AI combination.
Turnitin
- Strengths: Universal deployment in education. Long history of plagiarism detection methodology.
- Weaknesses: Disabled by major universities. Real-world FPR 5–20%. Strong demographic bias against non-native English and neurodivergent writers.
- Use case: Decreasingly defensible — increasingly being phased out.
The “bundled” detectors (Writer, Grammarly, SurgeGraph, BrandWell, Decopy AI)
- Strengths: Convenient, included with writing tools.
- Weaknesses: 0/9 on AI detection in 2026 Pangram comparison. Effectively non-functional.
- Use case: Skip entirely. The “AI detector” feature in your writing platform is marketing, not detection.
From Arvow: Track exactly how your client portfolio is cited across ChatGPT, Perplexity, Gemini, Claude, Grok, and Google AI Overviews — week over week — with Arvow’s LLM Visibility Tracker. LLM citation share is now a stronger predictor of brand presence than detector classification — and the distribution matters more than the average. Track Your AI Visibility →
9. The Contradictions: Why Detector Data Doesn’t Always Agree
The detector ecosystem has known disagreements. Here’s how to reason through them.
- Copyleaks vendor claim: 99.12% accuracy.
- Scribbr independent test: 66% accuracy.
Why they differ: vendors test on benchmarks they trained for. Independent benchmarks include adversarial conditions, paraphrasing, mixed authorship, non-native English. The right answer: use both numbers — vendor accuracy is an upper bound under ideal conditions; independent accuracy is the real-world floor.
- Same RAID dataset, two competing claims.
- Originality reports first-place finish in 9/11 adversarial tests.
- GPTZero’s cross-analysis derives Originality at 83% with 4.79% FPR.
Both can be true: Originality may rank highest in relative terms while still having absolute FPR around 5% (not the marketing 0.5%). RAID is the source-of-truth data — vendor framing diverges.
- Semrush 42K-page study: Position 1 is 8× more likely human.
- Rankability 487-result study: 83% of top results test as non-AI.
- Aggregated industry research: ~82% of high-ranking pages contain some AI content.
Both pictures can be true: high-ranking pages may use AI-assisted writing while the dominant style tests as human. The honest read: AI assistance ranks; AI-only content doesn’t reliably rank.
- Stanford (2023): 61.3% false positives on non-native English.
- Vendors (2024–2026): Most now claim bias-corrected models.
Independent re-tests on TOEFL-equivalent corpora aren’t widely published. The bias may be reduced, not eliminated. Treat vendor “we fixed it” claims with the same skepticism as the original “99% accuracy” claims.
- OpenAI’s classifier (Jan 2023): 26% accuracy. Shut down July 2023.
- Pangram (2024): 99.85% accuracy.
Possible reconciliations: Pangram’s methodology is genuinely better (hard negative mining with synthetic mirrors is a meaningful innovation); OR Pangram’s benchmark is calibrated favorably to its training. Both likely contribute. Triangulation across independent tests is the only honest read.
- Pangram benchmark: 99.85% accuracy + 0.19% FPR.
- Stanford: 61.3% false positives on a specific population.
Both can be true: detection works on specific test sets that resemble the training data, and fails on out-of-distribution content (non-native English, neurodivergent writers, heavily paraphrased text, short-form content). The category isn’t solved or broken — it’s brittle.
- General-purpose humanizers: QuillBot 47.4%, Grammarly 43.2% — coin flips.
- Top-tier humanizers (operating on sentence structure): can achieve 70%+ bypass against specific detectors.
The right answer: bypass is non-portable. A humanizer that defeats Originality may fail against GPTZero. A 70% bypass rate against a single detector is still a 30% expose rate against the cohort.
10. What This Means for You in 2026
Six concrete moves the data above actually justifies.
1. If you’re a publisher: don’t use a single detector as your gate.
The Arizona State / Advances in Physiology Education study (n=99) demonstrated empirically: aggregating multiple detectors reduces false-positive likelihood to near 0%. Use 3+ detectors; require consensus before action.
2. If you’re in academia: stop using detector output as evidence.
Vanderbilt’s institutional position (still operative): “AI detection scores should not be the sole basis for misconduct findings.” Multiple universities have followed. Use detection as a signal for closer review, not as adjudication.
3. If you’re a content marketer: don’t optimize for detector bypass.
- Position 1 is 8× more likely to be human-written (Semrush) — but the ranking signal is editorial depth + structural signals, not detector classification.
- Optimize for the signals that actually drive ranking: schema, internal linking, citation density, FAQ formatting, original data. See our pSEO piece §12.
- The arvow approach: ship content that has both human editorial judgment AND AI velocity. The detector classification is a downstream artifact, not the goal.
4. If you’re an agency: build the multi-detector workflow into delivery.
Per our Agency Statistics piece: 87% of marketers use AI in workflows. Agencies that ship content with explicit human-review documentation (3+ detector pass + editor signoff) are insulated against client disputes when Google’s “scaled content abuse” policy enforces.
5. If you’re evaluating a detector: ask for the independent benchmark.
Every vendor will quote their own 99% number. Ask: - What was the test set composition? - What was the false positive rate on non-native English? - What was the performance on humanized text? - What’s the RAID benchmark score?
A vendor that can’t answer those questions is selling marketing, not detection.
6. Track AI Overview citation share, not detector classification.
Per our AI Overviews piece: brands cited in AIOs win 35% more clicks. Detector classification is increasingly irrelevant — what matters is whether your content gets cited by LLMs and surfaced in AI Overviews. Use LLM Visibility Tracker for the citation-side measurement.
Ready to act on the data? Arvow’s AI SEO Agent automates the structural signals that drive ranking and LLM citation regardless of detector classification. Combined with Arvow’s Autoblog for content velocity and Arvow’s link building service for the link layer, that’s the full publication stack.
Or if you want to see the output first: Try 3 Free Articles →
Σ Summary: AI Content Detector Report 2026 by the Numbers
The 20 highest-leverage stats from this report, in one table.
| # | Stat | Source |
|---|---|---|
| 1 | AI Content Detection market: $1.79B (2025) → $6.96B by 2032 at 21.4% CAGR | Coherent Market Insights |
| 2 | Pangram Labs: 99.85% claimed accuracy, 0.19% FPR | Pangram technical report |
| 3 | GPTZero: 99.76% claimed accuracy, 0.08% FPR | GPTZero benchmarking |
| 4 | Originality.AI Lite: 99% claimed accuracy, 0.5% FPR | Originality.AI |
| 5 | Copyleaks claimed 99.12% — Scribbr independent test found 66% | Scribbr / GPTZero |
| 6 | Turnitin claimed <1% FPR — independent analyses find 5–20% | University of San Diego |
| 7 | OpenAI’s own classifier: 26% accuracy, 9% FPR — shut down July 2023 | OpenAI |
| 8 | Stanford: 61.3% of TOEFL essays falsely flagged as AI | James Zou et al., Patterns |
| 9 | All 7 detectors unanimously misclassified 19.8% of TOEFL essays | Stanford |
| 10 | ChatGPT-rewriting reduced FPR from 61.3% to 11.6% | Stanford |
| 11 | RAID benchmark: 6.28M texts across 8 domains, 11 LLMs, 12 detectors | UPenn / UCL / King’s / CMU |
| 12 | Originality.AI ranked #1 in 9 of 11 RAID adversarial tests | RAID / Originality.AI |
| 13 | Vanderbilt disabled Turnitin AI detector August 16, 2023 | Vanderbilt Brightspace |
| 14 | Vanderbilt’s math: 1% FPR × 75,000 papers/year = ~750 wrongly flagged | Vanderbilt |
| 15 | QuillBot humanizer bypass rate: 47.4%; Grammarly: 43.2% | Anangsha 2026 panel |
| 16 | Writer, Grammarly, SurgeGraph, BrandWell, Decopy AI: 0/9 on AI detection | Pangram 30-tool 2026 |
| 17 | Only Pangram + Copyleaks scored 9/9 AI + 3/3 human in 2026 head-to-head | Pangram Labs |
| 18 | Semrush 42K-page study: position 1 is 8× more likely human-written | Semrush 2025 |
| 19 | 86% of articles ranking on Google are human-written | Graphite Five Percent |
| 20 | GPTZero on 24 languages: 98.79% accuracy / 0.09% FPR; Originality: 91.46% / 14.81% FPR | GPTZero benchmarking |
Frequently Asked Questions
Are AI content detectors actually accurate?
Vendor claims of 99%+ accuracy are tested on the vendor’s own benchmark sets. Independent tests find real-world accuracy in the 66–92% range depending on the detector and dataset. Copyleaks claims 99.12% but Scribbr’s independent test found 66%. Originality.AI claims 99% but GPTZero’s RAID cross-analysis derives 83%. The honest read: detection works on clean AI content, degrades fast on humanized, paraphrased, or non-native English text.
Why did OpenAI shut down its own AI classifier?
OpenAI launched its AI text classifier on January 31, 2023, and shut it down on July 20, 2023 due to “low rate of accuracy.” Their disclosed performance: 26% accuracy on AI-written text, 9% false positive rate on human text, and “very unreliable” on texts below 1,000 characters. The company that built the underlying LLM concluded detection wasn’t shippable at scale in 2023.
Are AI detectors biased against non-native English speakers?
Yes — the Stanford / James Zou study (April 2023, published in Patterns) tested 7 detectors on 91 TOEFL essays from a Chinese forum. The average false-positive rate was 61.3%. All 7 detectors unanimously misclassified 19.8% of TOEFL essays as AI. At least one detector flagged 97.8% of them. The bias is rooted in “perplexity” scoring — non-native English writers tend to have lower lexical complexity that gets misclassified as AI.
What’s Turnitin’s real false positive rate?
Turnitin advertises a false positive rate of <1%. Independent analyses (per the University of San Diego Legal Research Center and others) find real-world FPR between 5% and 20% — 5–20× the vendor claim. This is why Vanderbilt, Michigan State, Northwestern, UT Austin, and Penn State have all disabled or recommended against Turnitin’s AI detection.
Can AI content rank on Google?
Yes, but the data shows clear position-by-position differences. Semrush’s 42,000-page study found position 1 results are 8× more likely to be human-written. From position 5 onwards, the human/AI gap narrows. Graphite’s Five Percent project found 86% of articles ranking on Google are human-written. Google’s official position: AI content is not penalized as a category — but low-quality content (much of which happens to be AI) gets demoted by SpamBrain and the helpful content system.
Do AI humanizers actually bypass detection?
General-purpose humanizers are coin flips in 2026. QuillBot’s AI humanizer: 47.4% average bypass rate against modern detectors. Grammarly’s humanizer (launched late 2025): 43.2%. Top-tier humanizers operating on sentence structure (not just vocabulary) can achieve 70%+ against specific detectors — but bypass is non-portable across detectors. Basic paraphrasing (synonym swaps) is empirically obsolete.
Which AI content detector is most accurate?
It depends on what you’re testing. Per the 2026 Pangram 30-tool head-to-head: only Pangram Labs and Copyleaks scored 9/9 on AI detection AND 3/3 on human detection. GPTZero leads on humanized text and multilingual content. Originality.AI ranks #1 in the RAID benchmark’s adversarial tests. The honest workflow: use 3+ detectors and require consensus — the Arizona State n=99 study showed aggregation reduces false-positive likelihood to near 0%.
Should I rely on a detector to decide if content is human or AI?
No. Every institutional review of detector reliability — Vanderbilt, Penn State, UK Office of the Independent Adjudicator — converges on the same conclusion: AI detection should be a signal for closer review, not adjudication. False positive rates of 5–20% mean a meaningful portion of human content gets wrongly flagged. Detector output is direction, not evidence.
Will watermarking solve this?
If OpenAI and Anthropic ship cryptographic watermarking at scale, the downstream detector category becomes structurally obsolete — detection becomes a watermark lookup, not a perplexity classification. As of May 2026, neither has shipped at production scale. Proposals exist; deployment lags.
What’s the right strategy if I publish AI-assisted content?
Per our pSEO piece §12: optimize for the structural signals that survive Google updates and earn LLM citations — schema, internal linking, citation density, original data, FAQ formatting — not for detector bypass. The detector classification of your content is a downstream artifact of writing quality, not a primary goal.
Methodology and Sources
This report aggregates data from 25+ primary sources published between 2023 and May 2026, with priority on:
- Peer-reviewed academic studies with disclosed methodology and sample sizes — Stanford / James Zou et al. in Patterns (Cell Press, 2023, n=91 TOEFL + n=88 US); RAID benchmark (UPenn / UCL / King’s / CMU, n=6.28M texts); Arizona State / Advances in Physiology Education (2024, n=99 essays); DAMAGE adversarial paper (arXiv, January 2025)
- Vendor-published benchmarks with disclosed methodology — Pangram Labs (8 LLMs × 10 writing categories), GPTZero (4-domain + multilingual + bypasser), Originality.AI (Lite + Turbo + RAID), Copyleaks, Turnitin
- Independent comparison tests — Pangram 30-tool 2026, Scribbr 12-tool, CyberNews single-tool benchmarks, Anangsha humanizer 30+ tool panel
- Institutional policy documents — Vanderbilt Brightspace (Aug 2023), Penn State, multiple US universities
- First-party platform disclosures — OpenAI classifier shutdown notice (July 2023), Google Search Central policy documentation
- Industry market sizing — Coherent Market Insights, MarketsAndMarkets, Grand View Research
Primary sources used
- Stanford HAI / James Zou et al. (GPT detectors are biased, arXiv paper)
- OpenAI (AI Classifier announcement)
- Vanderbilt University (Brightspace guidance on disabling Turnitin AI detection)
- Pangram Labs (Best AI Detector Tools 2026 30-tool comparison, Technical Report)
- GPTZero (Benchmarking, vs Copyleaks vs Originality)
- Originality.AI (14-study meta-analysis, RAID analysis, Accuracy claims)
- Copyleaks (Self-reported accuracy)
- Coherent Market Insights (AI Content Detection Software Market)
- Advances in Physiology Education (STEM-Student aggregation study)
- Semrush (Does AI content rank?)
- Rankability (Does Google penalize AI)
- Graphite Five Percent project (AI content in search and LLMs)
- The Register (Universities reject Turnitin’s AI detector)
- Times Higher Education (Students win plagiarism appeals over AI detection)
- Spectrum Local News (University at Buffalo student petition)
- arXiv (DAMAGE adversarial humanizer paper)
- Anangsha Alammyan / Freelancer’s Hub (30+ humanizer test 2026)
- University of San Diego Legal Research Center (False positives and negatives in detection)
- Google Search Central (Core update + spam policies March 2024)
This page was last updated May 2026. Bookmark it — we update quarterly as Pangram, GPTZero, Originality.AI, RAID, and the academic literature publish new data.
Keep reading

Generate, publish, syndicate and update articles automatically
The AI SEO Writer that Auto-Publishes to your Blog
- Cancel anytime
- Articles in 30 secs
- Plagiarism Free